Active Recognition
Active Object Recognition
The lab has been a pioneer in this topic, with the first successful implementation of an active recognition method by D. Wilkes at CVPR 1992.
Publications
Dickinson, S., Wilkes, D., Tsotsos, J., A computational model of view degeneracy, IEEE Transactions on Pattern Analysis and Machine Intelligence, 21(8), p673-689, 1999.
Wilkes, D., Dickinson, S., Tsotsos, J., A quantitative analysis of view degeneracy and its use for active focal length control, International Conference on Computer Vision, Cambridge MA, June 1995.
D. Wilkes, S. Dickinson, and J.K. Tsotsos, A computational model of view degeneracy and its application to active focal length control, LCSR-TR-231, Rutgers University, Oct. 1994.
D. Wilkes, S. Dickinson, and J.K. Tsotsos, Quantitative Modelling of View Degeneracy, Proceedings of the Eighth Scandinavian Conference on Image Analysis, Tromso, Norway, May 1993.
Wilkes, D., Tsotsos, J., Integration of camera motion behaviours for active object recognition, Proc. Int. Association for Pattern Recognition Workshop on Visual Behaviors, p 10 – 19, Seattle, June 1994.
Wilkes, D., Tsotsos, J., Behaviors for Active Object Recognition, Proceedings Volume 2055: Intelligent Robots and Computer Vision XII: Algorithms and Techniques, p 225 – 239, Boston, Sept. 1993
D. Wilkes, S. Dickinson, and J.K. Tsotsos, Quantitative Modelling of View Degeneracy, ARK93-PUB-10, March 1993.
Wilkes, D., Tsotsos, J.K., Active Object Recognition, CVPR-92, Urbana, Ill, 1992, p 136 – 141.
Vision-Based Fallen Person Detection for the Elderly
Falls are serious and costly for elderly people. The Centers for Disease Control and Prevention of the US reports that millions of older people, 65 and older, fall each year at least once. With this project we are working on a new, non-invasive system for fallen people detection. Our goal is to use only stereo camera data for passively sensing the environment.
The key novelty is a human fall detector which uses a CNN based human pose estimator in combination with stereo data to reconstruct the human pose in 3D and estimate the ground plane in 3D. Furthermore, a reasoning module is proposed which formulates a number of measures to reason whether a person is fallen. Based on our extensive evaluations, our system shows high accuracy and almost no miss-classification.

Publications
Solbach, Markus D., and John K. Tsotsos. “Vision-based fallen person detection for the elderly.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
Random Polyhedral Scenes: An Image Generator for Active Vision System Experiments
This project is specifically designed to support research in active perception by generating images of scenes with known complexity characteristics and with verifiable properties with respect to the distribution of features across a population. Thus, it is well-suited for research in active perception without the requirement of a live 3D environment and mobile sensing agent, including comparative performance evaluations.
Creates a random scene based on a few user parameters, renders the scene from random viewpoints, then creates a data set containing the renderings and corresponding annotation files. The system provides a web-interface as well as a RESTful API.

Publications
Solbach, Markus D., et al. “Random Polyhedral Scenes: An Image Generator for Active Vision System Experiments.” arXiv preprint arXiv:1803.10100 (2018).
Active Observers in a 3D World: The Same-Different Task
There are many examples where a robot that can act as an active observer would be useful. In this project, we focus on the perception-feedback component of the active visual processing pipeline – We want to understand how human subjects use multiple views to recognize objects. To limit the scope of the problem, we study how humans might solve a variation of the popular Same-Different Task and assert that this is a basic perceptual ability. We wish to discover the underlying strategies that are used by humans to solve the 3D Same-Different Taskas active observers. We introduced the 3D Same-Different Task for active observers. Created a novel set of 3D objects with known complexity. We established that the orientation between the two presented objects has a large influence on the subject’s performance – both qualitatively and quantitatively.

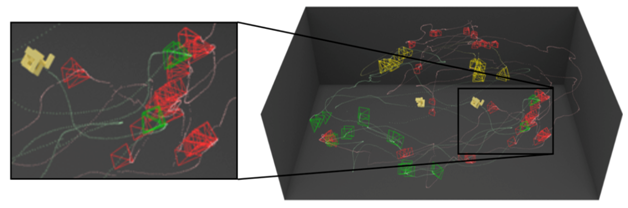
Publications
Tsotsos, John K., et al. “Visual attention and its intimate links to spatial cognition.” Cognitive processing 19.1 (2018): 121-130.
Autonomous visual search
The objective of this project is to examine how visual cues in an unknown environment can be extracted and used to improve the efficiency of visual search conducted by an autonomous mobile robot. We want to investigate different attentional mechanisms, such as bottom-up and top-down visual saliency, and their effects on the way the robot finds an object.
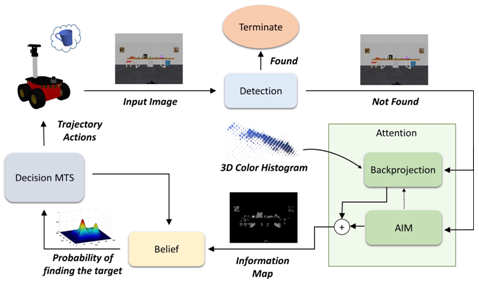

Key Results
Visual saliency, both bottom-up and top-down, was shown to significantly improve the visual search process in unknown environments. Saliency serves as a mechanism to identify cues that can lead the robot to locations where the target is more likely to be detected. The efficiency of saliency mechanisms, however, highly depends on the characteristics of the object, e.g. its similarity to the surrounding environment, and the structure of the search environment.
Publications
A. Rasouli, P. Lanillos, G. Cheng, and J. K. Tsotsos, “Attention-based active visual search for mobile robots,” The Journal of Autonomous Robots, 2019.
A. Rasouli and J. K. Tsotsos, “Integrating three mechanisms of visual attention for active visual search,” in 8th International Symposium on Attention in Cognitive Systems IROS, Hamburg, Germany, Sep. 2015.
A. Rasouli and J. K. Tsotsos, “Visual saliency improves autonomous visual search,” In Proc. Conference on Computer and Robot Vision (CRV), 2014, pp. 111–118.
Active Inductive Inference
The main point of this project is to examine the definition of attention presented in Tsotsos (2011), namely attention is the process by which the brain controls and tunes information processing, and to show how it applies much more broadly than just to visual perception. Visual perception is part of active agents, whether biological or machine, and as such must be effectively integrated into an overall cognitive system that behaves purposely in the real word. This points to the need to expand consideration to include active observers and reasoners. It is not difficult to argue against any purely passive perceptual framework. Passive perception gives up control, and thus any agent that relies on it cannot assert purpose to its behaviour. A passive sensing strategy, no matter how much data are collected, no matter how high the quality of statistics extracted, gives up control over the specific characteristics of what is sensed and at what time and for which purpose. Passive sensing reduces or eliminates the utility of any form of predictive reasoning strategy (hypothesize and test, verification of inductive inferences including Bayesian, etc.). Everyday behaviour relies on sequences of perceptual, decision-making and physical actions selected from a large set of elemental capabilities. It is known that the problem of selecting a sequence of actions to satisfy a goal under resource constraints is known to be NP-hard (Ye and Tsotsos 2001). Humans are remarkably capable regardless. It is a challenge to discover exactly how they are so capable. Inductive inference takes specific premises and makes a broader generalization (conclusion) that is considered probable In a real world (no closed world assumption), conclusions can only be confirmed by an actual test To do so, the system needs to actively tune itself for this test in order to best acquire that data needed.

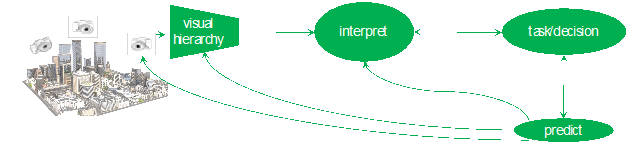
Publications
Tsotsos, J. K., Kotseruba, I., Rasouli, A., & Solbach, M. D. (2018). Visual attention and its intimate links to spatial cognition. Cognitive processing, 19(1), 121-130.
Bajcsy, R., Aloimonos, Y., & Tsotsos, J. K. (2018). Revisiting active perception. Autonomous Robots, 42(2), 177-196.