Vision Architecture
Totally-Looks Like: Totally Looks Like-How Humans Compare, Compared to Machines
Perceptual judgment of image similarity by humans relies on rich internal representations ranging from low-level features to high-level concepts, scene properties and even cultural associations. Existing methods and datasets attempting to explain perceived similarity use stimuli which arguably do not cover the full breadth of factors that affect human similarity judgments, even those geared toward this goal. We introduce a new dataset and show that current state-of-the-art techniques do not suffice.
Dataset with 6016 image-pairs from the wild, shedding light upon a rich and diverse set of criteria employed by human beings. We conduct experiments to try to reproduce the pairings via features extracted from state- of-the-art deep convolutional neural networks, as well as additional human experiments to verify the consistency of the collected data.

Publications
Rosenfeld, Amir, Markus D. Solbach, and John K. Tsotsos. “Totally looks like-how humans compare, compared to machines.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2018.
Rosenfeld, Amir, Markus Solbach, and John Tsotsos. “Totally-Looks-Like: A Dataset and Benchmark of Semantic Image Similarity.” Journal of Vision 18.10 (2018): 136-136.
STNet: Selective Tuning of Convolutional Networks for Object Localization
Visual attention modeling has recently gained momentum in developing visual hierarchies provided by Convolutional Neural Networks. Despite recent successes of feedforward processing on the abstraction of concepts form raw images, the inherent nature of feedback processing has remained computationally controversial. Inspired by the computational models of covert visual attention, we propose the Selective Tuning of Convolutional Networks (STNet). It is composed of both streams of Bottom-Up and Top-Down information processing to selectively tune the visual representation of Convolutional networks. We experimentally evaluate the performance of STNet for the weakly-supervised localization task on the ImageNet benchmark dataset. We demonstrate that STNet not only successfully surpasses the state-of-the-art results but also generates attention-driven class hypothesis maps.
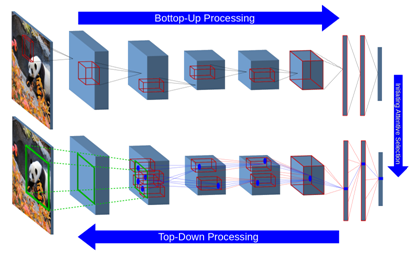

Publications
Biparva, John Tsotsos, STNet: Selective Tuning of Convolutional Networks for Object Localization, The IEEE International Conference on Computer Vision (ICCV) Workshops, 2017, pp. 2715-2723
Priming Neural Networks
Visual priming is known to affect the human visual system to allow detection of scene elements, even those that may have been near unnoticeable before, such as the presence of camouflaged animals. This process has been shown to be an effect of top-down signaling in the visual system triggered by the said cue. In this paper, we propose a mechanism to mimic the process of priming in the context of object detection and segmentation. We view priming as having a modulatory, cue dependent effect on layers of features within a network. Our results show how such a process can be complementary to, and at times more effective than simple post-processing applied to the output of the network, notably so in cases where the object is hard to detect such as in severe noise. Moreover, we find the effects of priming are sometimes stronger when early visual layers are affected. Overall, our experiments confirm that top-down signals can go a long way in improving object detection and segmentation.

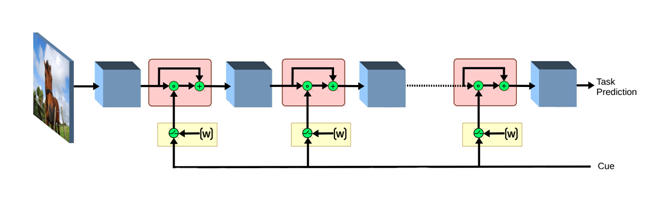
Publications
Rosenfeld, Amir and Biparva, Mahdi and Tsotsos, John K., Priming Neural Networks, The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June, 2018
STAR-FC
The Selective Tuning Attentive Reference Fixation Control (STAR-FC) model provides a dynamic representation of attentional priority as it predicts an explicit saccadic sequence over visual input, moving beyond a static saliency representation for fixation prediction. STAR-FC provides a link between saliency and higher level models of visual cognition, and serves as a useful module for a broader active vision architecture.
equence over visual input, moving beyond a static saliency representation for fixation prediction. STAR-FC provides a link between saliency and higher level models of visual cognition, and serves as a useful module for a broader active vision architecture.
Key results
– High fidelity reproduction of the first five fixations over an image
– Qualitatively more natural sequence structure for long duration saccade sequences
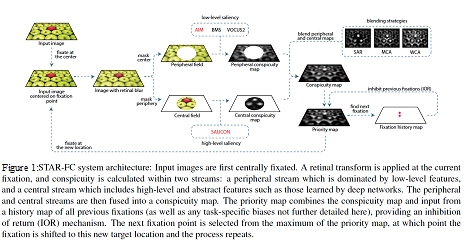
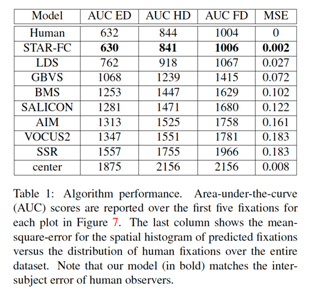
Publications
Calden Wloka, Iuliia Kotseruba, and John K. Tsotsos (2018) Active Fixation Control to Predict Saccade Sequences. Proc. of Conference on Computer Vision and Pattern Recognition (CVPR)
John K. Tsotsos, Iuliia Kotseruba, and Calden Wloka (2016) A Focus on Selection for Fixation. Journal of Eye Movement Research 9(5):2,1-34
Code is available from https://github.com/TsotsosLab/STAR-FC
For more information visit:
http://www.cse.yorku.ca/~calden/projects/fixation_control.html
STAR-FCT
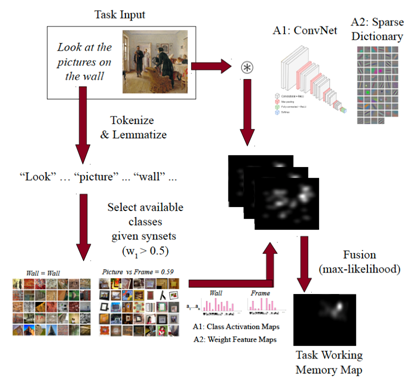
In this work we propose an architecture to enable tuning of attentional processing mechanisms to adapt vision given specific task instructions. We will extend to the Selective Tuning Attentive Reference Fixation Controller (STAR-FC) by incorporating:
– Long-Term Memory (LTM) for Symbolic and Visual Representations
– Task Working Memory (tWM) for Location bias with respect task specification
– Visual Task Executive (vTE) to Fetch methods from LTM to Hierarchy & tWM
We hope to provide low- and high-level feature basis for the visual memory representations, to define a hierarchical lexico-semantic memory explaining the task specification, determine influences of task over fixations (including memory, covert and overt attention).
This work is led by our collaborator, Dr. David Berga, Computer Vision Center, Autonomous University of Barcelona, Spain.
Publications
Berga D, Wloka C, Tsotsos JK and Lassonde School of Engineering – York University. Modeling task influences for saccade sequence and visual relevance prediction. F1000Research 2019, 8:820 (poster) (https://doi.org/10.7490/f1000research.1116873.1)
40 Years of Cognitive Architectures
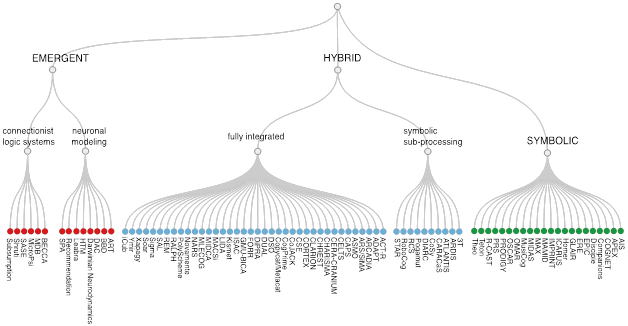
A large-scale survey of 84 cognitive architectures developed in the past four decades. We summarized and catalogued various approaches to designing the architectures and their individual components. We also assessed the extent to which these architectures implement various human cognitive abilities, e.g. perception (vision), attention, memory, learning, etc. Finally, we examined the practical applicability of these approaches by aggregating information on over 900 practical applications that were implemented using the cognitive architectures in our list.
Key results
This is currently the largest analysis of the past and current work in this field; it has been downloaded nearly 9,000 time and is used in several university courses as additional reading material; keynote talk at 2018 Fall AAAI Symposium.
Publications
I. Kotseruba, J.K. Tsotsos, “40 years of cognitive architectures: core cognitive abilities and practical applications.” Artificial Intelligence Review (2018): 1-78.
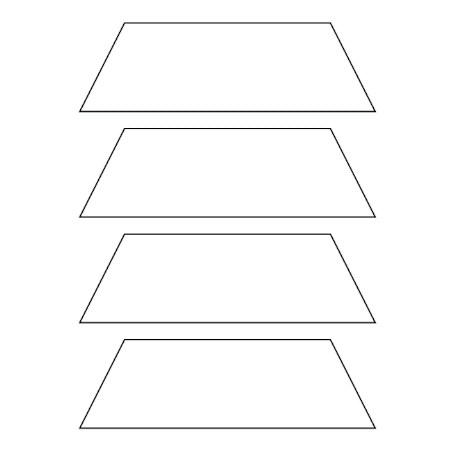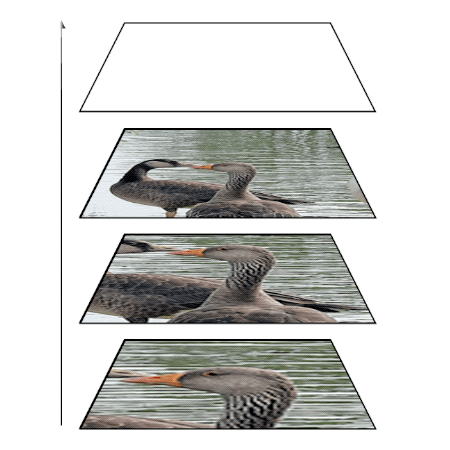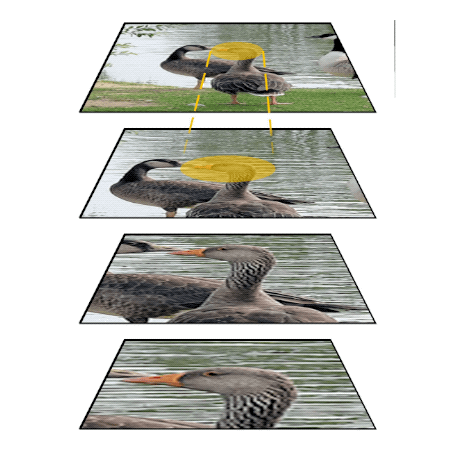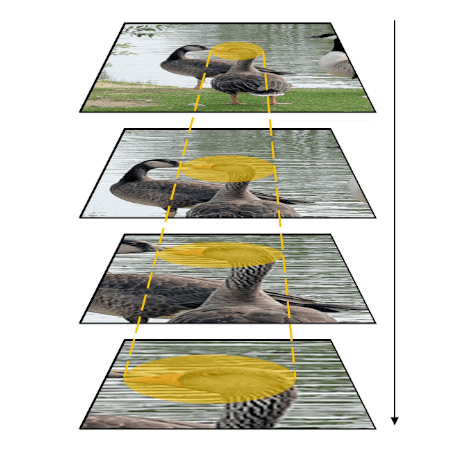
The roles of top-down feedback processing in visual perception
People can perform simple visual tasks very rapidly and accurately, suggesting the sufficiency of feed-forward visual processing for these tasks. However, more complex visual tasks may require top-down feedback processing to access fine-grained information available at earlier processing levels in the visual hierarchy, thus, additional processing time is needed for this downward traversal. The goal of this project is measuring processing time taken to complete different visual recognition tasks (detection and localization of targets) in simple or complex visual scenes. Task performance in simple scenes becomes asymptotic within a short period of time. On the other hand, task performance in cluttered scenes improves when additional processing time is allowed, indicating that slow, time-consuming top-down feedback processing contributes to analyze elements in complex visual scenes.
This work is in collaboration with Dr. Mazyar Fallah, York University, Toronto, Canada.
Publications
Yoo, S-. A., Tsotsos, J. K., & Fallah, M. (under revision). Feed-forward visual processing suffices for coarse localization but precise localization in a complex context needs feedback processing.
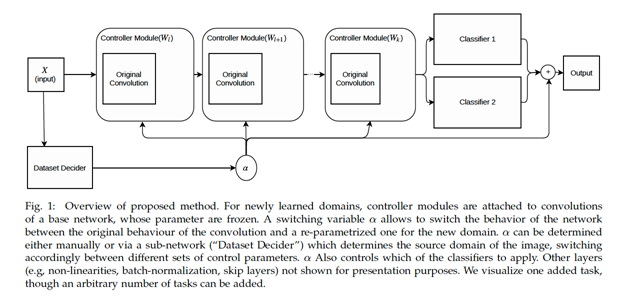
Adaptive Representations
Easily use learned representations for new tasks. An alternative to transfer learning that fully eliminates catastrophic forgetting, while requiring significantly less parameters and converges faster.
Publication
Rosenfeld, A., & Tsotsos, J. K. (2018). Incremental learning through deep adaptation. IEEE transactions on pattern analysis and machine intelligence.
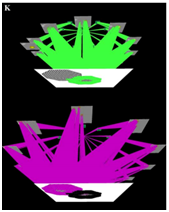
Selective Tuning of Convolutional Network for Affine Motion Pattern Classification and Localization
Tsotsos et al. (2004) present the first motion-processing model to include a multi-level decomposition with local spatial-derivatives of velocity and demonstrated localization of motion patterns using selective tuning. Later, Vintila and Tsotsos (2007) present motion detection and estimation for attending to visual motion using orientation tensor formalism method. Velocity field is extracted using a model with 9 quadrature filters. Here we try to develop a learning framework for these motions with the same goal: Classify affine motion patterns using convolutional network and localize motion patterns using selective tuning algorithm. Evaluate performance of different network architectures on these tasks.
Key Results

Publications
Vintila, F., Tsotsos, J.K., Motion Estimation using a General Purpose Neural Network Simulator for Visual Attention, IEEE Workshop: Applications of Computer Vision, Austin, Texas, Feb. 21-22, 2007.
Tsotsos, J.K., Liu, Y., Martinez-Trujillo, J., Pomplun, M., Simine, E., Zhou, K., Attending to Visual Motion, Computer Vision and Image Understanding 100(1-2), p 3 – 40, Oct. 2005.
Shortcomings of Deep Learning vs the Human Visual System
Find where current computer-vision severely lacks w.r.t human vision in order to improve the former. In short: revealing a family of errors made by state-of-the-art object detectors, induced by simple copying and pasting of learned objects in arbitrary image locations. It is suggested that these errors stem from the lack of a mechanism for inhibiting interfering signals within the receptive field of the detector.

Link to the youtube video
Publication
Rosenfeld, A., Zemel, R., & Tsotsos, J. K. (2018). The elephant in the room. arXiv preprint arXiv:1808.03305.
Attentive Compact Neural Representation
Deep neural networks have evolved to become power demanding and consequently difficult to apply to small-size mobile platforms. Network parameter reduction methods have been introduced to systematically deal with the computational and memory complexity of deep networks. We propose to examine the ability of attentive connection pruning to deal with redundancy reduction in neural networks as a contribution to the reduction of computational demand. In this chapter, we describe a Top-Down attention mechanism that is added to a Bottom-Up feedforward network to select important connections and subsequently prune redundant ones at all parametric layers. Our method not only introduces a novel hierarchical selection mechanism as the basis of pruning but also remains competitive with previous ad hoc methods in experimental evaluation. We conduct experiments using different network architectures on popular benchmark datasets to show high compression rate is achievable with negligible loss of accuracy.
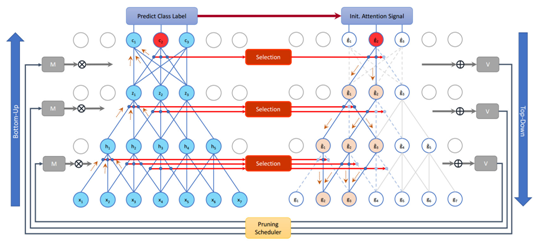
Publications
Biparva, M., Top-Down Selection in Convolutional Neural Networks, Doctoral Dissertation, Dept. of Electrical Engineering and Computer Science, York University, September 2019.
Contextual Interference Reduction by Focusing on Attentional Traces
The issue of the contextual interference with the foreground target objects is one of the main shortcomings of the hierarchical feature representations such as convolutional neural networks. Due to the dense hierarchical parametrization of convolutional neural networks and the utilization of convolution and sub-sampling layers in the feedforward manner, foreground and background representations are inevitably mixed up and visual confusion is eminent. A systematic approach to shift learned neural representations from the emphasis on the contextual regions to the foreground target objects can help achieve a higher degree of representation disentanglement. We propose a selective fine-tuning approach for neural networks using a unified bottom-up and top-down framework. A gating mechanism of hidden activities imposed by Top-Down selection mechanisms is defined in the iterative feedforward pass. An attention-augmented loss function is introduced using which the network parameters are fine-tuned for a number of iterations. The fine-tuning using the iterative pass helps the network to reduce the reliance on the contextual representation throughout the visual hierarchy. Therefore, the label prediction relies more on the target object representation and consequently achieve a higher degree of robustness to the background changes.
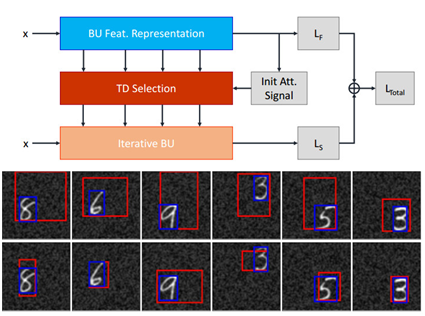
Publications
Biparva, M., Top-Down Selection in Convolutional Neural Networks, Doctoral Dissertation, Dept. of Electrical Engineering and Computer Science, York University, September 2019.